Introduce riscv vector.
vector指令集想要解决的事情是:普通标量指令集每条指令只可操作一个目的寄存器,如果想要有多次类似的操作,需要用多条指令来完成,而使用vector可以达到,一条指令操作多个寄存器或内存地址。
Term
ELEN
The maximum size in bits of a vector element that any operation can produce or consume, ELEN ≥ 8, which must be a power of 2.
最大可操作element的大小。必须大于等于8。
VLEN
The number of bits in a vector register, VLEN>=ELEN, which must be a power of 2.
vector寄存器的bits,就是VLEN。要求 VLEN>= ELEN。
SEW
Selected element width.
当前选择的element宽度。它会把vector register分成多分。
LMUL
Vector register group multiplier.
把多个vector寄存器打包成一个group。取值是1/8,1/4,1/2,1,2,4,8。
VLMAX
The maximum number of elements that can be operated on with a single vector instruction given the current SEW and LMUL settings.
每条指令可操作的最大elements个数。
VLMAX = LMUL * VLEN / SEW
vl
vector length.
本次指令要操作的element个数。vl <= VLMAX
vstart
本次指令操作的起始element序号。
解释
VLEN是cpu design设计完就定死了的。
SEW和LMUL是软件在使用的时候用指令配置到vtype寄存器里的,是可以更改的。
一旦配置了SEW和LMUL,那VLMAX就确定了,后面的vector指令可操作的最大element个数就确定了。后面的vector指令操作的element个数可以小于VLMAX,它是通过vl寄存器来指定的。
一个指令操作的宽度:LMUL* VLEN。这个指令里面的操作元素的宽度是SEW。
例子
假设VLEN=128bit。
当VLEN=SLEN,LMUL=1的时候,我们来看看SEW的含义。
| Byte | F | E | D | C | B | A | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEW=8 bit | F | E | D | C | B | A | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| SEW=16 bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | ||||||||
| SEW=32 bit | 3 | 2 | 1 | 0 | ||||||||||||
| SEW=64 bit | 1 | 0 | ||||||||||||||
| SEW=128 bit | 0 |
可以看出,当SEW为8bit的时候,一个vector register被分成了16份,每份8bit。当SEW为128bit时,一个vector register被分成了1份,每份128bit。
再来看看LMUL的含义。
当VLEN=SLEN,LMUL=1/4的时候。一个vector register只有1/4有效,所以最大SEW也就只能取到32bit了。这里可能会有个疑问,这样子看怎么表示中间的有效呢。这就要引出vstart和vl的概念了,vstart表示从哪个index开始,vl表示到哪个index结束。
| Byte | F | E | D | C | B | A | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEW=8 bit | - | - | - | - | - | - | - | - | - | - | - | - | 3 | 2 | 1 | 0 |
| SEW=16 bit | - | - | - | - | - | - | 1 | 0 | ||||||||
| SEW=32 bit | - | - | - | 0 |
当VLEN=SLEN,SEW=32,LMUL=2的时候。每次操作2个vector register,相应的序号就如下所示。
| Byte | F | E | D | C | B | A | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| v2*n | 3 | 2 | 1 | 0 | ||||||||||||
| v2*n+1 | 7 | 6 | 5 | 4 |
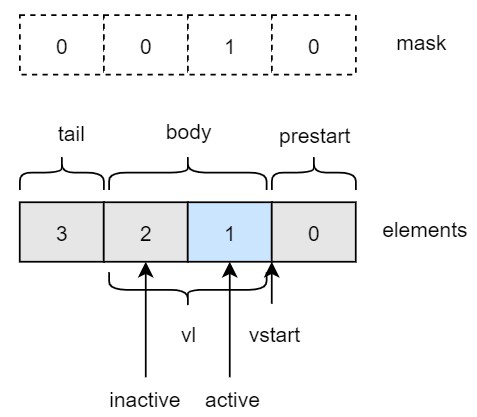
Prestart, Active, Inactive, Body, and Tail
这几个概念是针对element来说的。
假设VLEN=32,LMUL=2,SEW=16,那么这条指令需要操作4个元素。如果vstart设置为1,vl设置为2,那这些概念对应的分别是如图所示。
1 | for element index x |
Programmer’s model
为vector增加了32个vector register,并加了7个unprivileged CSR,以及在mstatus/vsstatus里面增加了相应的域。
可以看出,vector对于privilege的改动基本不大。大多数CSR都是为了不破坏32 bit指令编码而设置。
vector register
32个vector register,v0~v32。和scalar的类似,不过v0不是固定为0,而是会默认为mask。每个register是VLEN长度。
privilege
mstatus[10:9]中增加了VS域,它和FS域类似。
当mstatus.VS是OFF的时候,执行任何vector指令,或访问vector CSRs,会产生illegal instruction异常。
当mstatus.VS是initial或clean,执行任意会改变vector状态的指令(包括vector CSRs),会将mstatus.VS改为dirty。implementations可能会在任意时刻将mstatus.VS从initial或clean改为dirty,即使没有vector状态的改变。
如果mstatus.VS是dirty,mstatus.SD为1。
在misa中增加了V域。
同样的,如果hypervisor实现了,那再vsstatus里也增加VS域。
unprivileged
| Address | Privilege | Name | Description |
|---|---|---|---|
| 0x008 | URW | vstart | Vector start position |
| 0x009 | URW | vxsat | Fixed-Point Saturate Flag |
| 0x00A | URW | vxrm | Fixed-Point Rounding Mode |
| 0x00F | URW | vcsr | Vector control and status register |
| 0xC20 | URO | vl | Vector length |
| 0xC21 | URO | vtype | Vector data type register |
| 0xC22 | URO | vlenb | VLEN/8 (vector register length in bytes) |
vstart,定义指令的起始元素位置
vxsat,定点饱和标志
vxrm,定点rounding mode
vcsr,里面就是vxsat和vxrm,为什么要再设置一个这个寄存器,不懂。
vl,本条指令需要操作的元素个数
vtype,设置的SEW/LMUL
vlenb,告诉软件该硬件的VLEN是多少。
vtype里面除了SEW/LMUL,还有两个vta(vector mask agnostic)和vma(vector tail agnostic)。
因为vector操作会有很多空洞,比如tail,比如inactive,那这些位置的值,是保留原值,还是填固定值,就涉及不同策略了。如果是需要保留原值,那硬件在处理时是需要更多消耗的。为了平衡软件硬件,才设置了不同的策略。
undisturbed:保留原值
agnostic:允许保留原值,也允许填1
vector instruction
共有如下几种指令类型:
- configuration setting instructions
- vector loads and stores instructions
- vector integer arithmetic instructions
- vector fixed-point arithmetic instructions
- vector floating-point arithmetic instructions
- vector reduction instructions
- vector mask instructions
- vector permutation instructions
configuration setting instructions
提供了三条配置指令。
1 | vsetvli rd, rs1, vtypei # rd = new vl, rs1 = AVL, vtypei = new vtype setting |
它们实现的动作是:
- 将新的vtype配置(SEW/LMUL/vta/vma)写入vtype
- 根据新的vtype,和AVL,计算出新的vl,并写入vl
- 再将新的vl,写入rd
- 如果配置不支持,就vtype里的vill置为一,vtype的其他域清零,vl也清零
这里比较特殊的是AVL(application vector length),它是期望的长度,是可以大于VLMAX的,所以计算出来的新的vl不一定会等于AVL。
举个例子说明。假设VLEN=64,SEW=8,LMUL=2,AVL=32。那么一次可以操作VLENLMUL/SEW = 64 2 / 8 = 16 个元素。那么vl会被写入16,该笔请求需要做32/16=2次才能做完。
对于vl的值的计算,有如下规则要遵守。
- vl = AVL if AVL <= VLMAX. 这点比较好理解,如果期望操作的元素个数小于,最大可以操作的元素个数,那本次操作的就是AVL。
- ceil( AVL / 2) <= vl <= VLMAX if AVL < (2VLMAX). 这点不好理解,我觉得是,如果AVL < 2 VLMAX,那就一定得分两次做了,那它允许implementation决定以怎样的方式分两次。比如,假设VLMAX=16,AVL=28,那允许16+12,也允许14+14,也允许15+13。
- vl = VLMAX if AVL >= (2*VLMAX),如果大于2倍的VLMAX,那就必须按最多的来做了。
vector loads and stores instructions
vector loads stores指令分为以下几种
- unit-stride
- unit-stride, whole register
- unit-stride, mask, EEW=8
- unit-stride fault-only-first
- strided
- indexed-unordered
- indexed-ordered
- unit-stride segment
- unit-stride fault-only-first segment
- stride segment
- indexed-unordered segment
- indexed-ordered segment
在load/store指令中,还可以指定EEW,也就是本次需要读写的element宽度,通过公式可以得到EMUL。
1 | EMUL == (EEW / SEW) * LMUL |
也就是,根据原SEW/LMUL计算得到本次要操作的个数 vl = VLEN/SEW*LMUL,即使重新指令EEW,也就是重新指定了每个元素的宽度,但是本次要操作的个数vl是不变的。
unit-stride
单位步长,也就是连续的load/store,固定步长的。
1 | # Vector unit-stride loads and stores |
举例说明。假设VLEN=128。
场景:SEW=8,LMUL=1,EEW=SEW
1 | li a0, 0x90000000 |
场景:SEW=8,LMUL=1,EEW=2*SEW,说明EEW比SEW大的情况
1 | li a0, 0x90000000 |
场景:SEW=8,LMUL=1,EEW=(1/4)*SEW,说明EEW比SEW小的情况
1 | li a0, 0x90000000 |
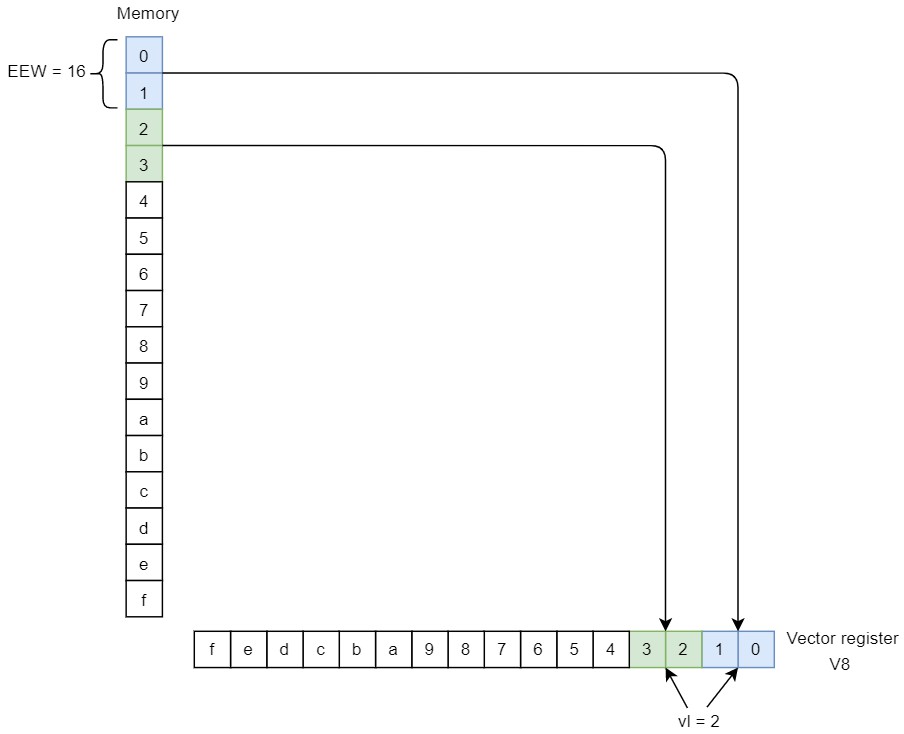
从上面的例子看出:
- unit-stride的访问元素个数,是根据vsetvli指令计算出的vl
- unit-stride的访问元素位宽,是指令里的EEW,它和SEW可以不同,以EEW为准
- unit-stride的访问,小地址写到寄存器低位
unit-stride, whole register
读写一个完成的寄存器。指令码中的nf域指定了load/store多少个vector寄存器。目前NFIELDS支持1/2/4/8。
这种指令忽略vtype和vl寄存器。只与nf和EEW有关。evl = NFIELDS * VLEN / EEW。
1 | # Format of whole register load and store instructions |
这里特殊的是,load可以指定EEW,但是store不能指定EEW,仅支持EEW=8。这里不理解为什么让load可以指定,而store不能指定?
举例说明。假设VLEN=128。
1 | vl1re64.v v8, (a0) |
unit-stride, mask, EEW=8
该条指令和vle类似的,也是从memory中load/store值出来,EEW固定为8,不同的是 evl = ceil(vl/8),也就是vl/8向上取整。
1 | # Vector unit-stride mask load/store |
举例说明。假设VLEN=128。
1 | li a1, 127 |
unit-stride fault-only-first
只有在元素0发生异常时,才会发生trap;在其他元素发生异常时,不发生trap。
1 | # Vector unit-stride fault-only-first loads |
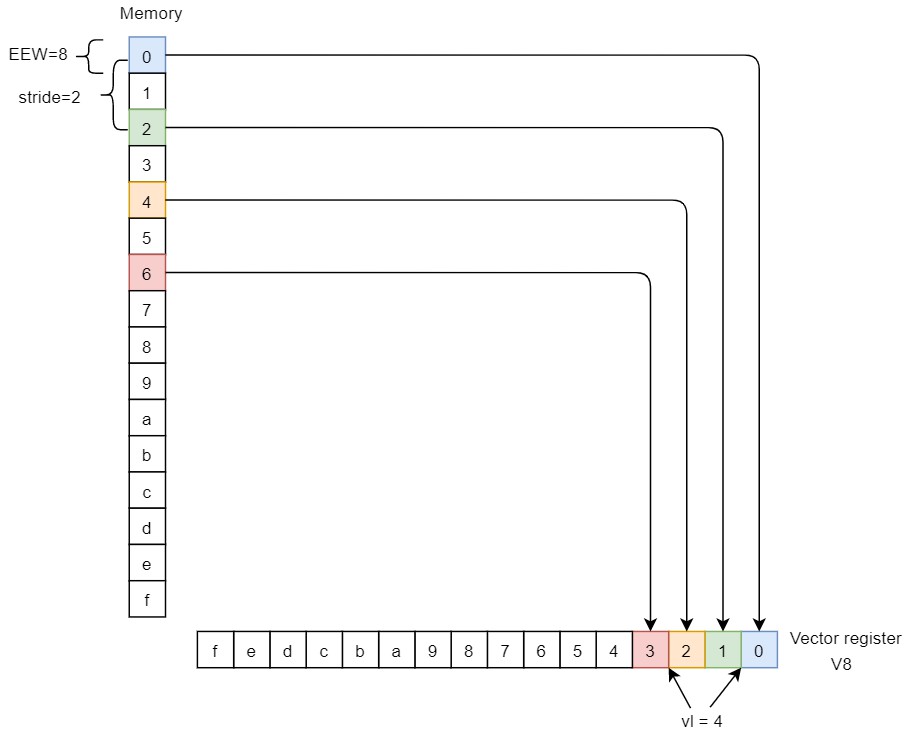
strided
指定步长的。
1 | # Vector strided loads and stores |
该指令的几个特殊情况:
- negative and zero strides 是支持的。负数和0作为步进都支持。
- 每个元素是unordered的。
- 当rs2 = x0,implementation可以支持,也可以不支持。
- 当rs2 != x0,但是x[rs2] = 0,implementation 必须为每个元素执行一次memory访问,这些访问可能unordered。
举例说明。假设VLEN=128。
1 | li a1, 512 |
indexed-unordered
可以指定index。
1 | # Vector indexed loads and stores |
举例说明。假设VLEN=128。
1 | li a1, 512 |
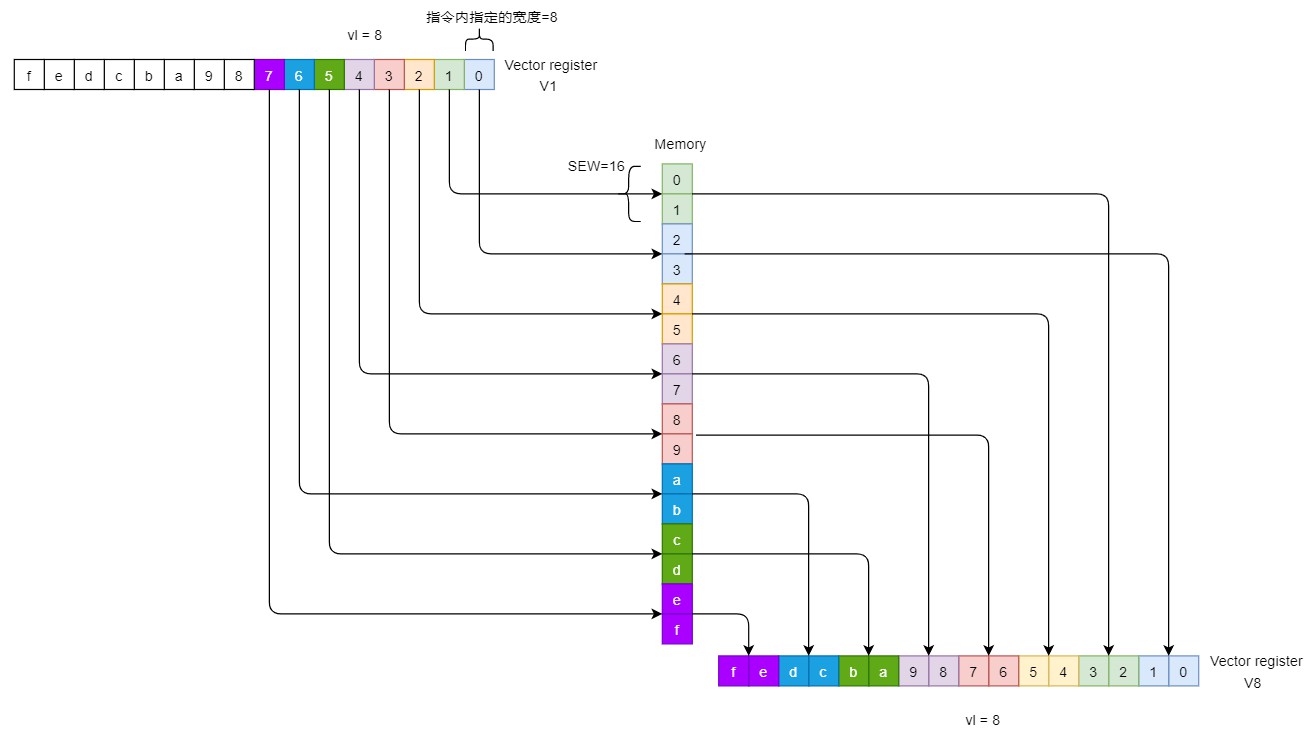
有几个特点:
- index指的是地址的偏移,而不是元素个数的偏移
- vs2的每个元素的宽度是指令指定的。访问的宽度是SEW。
indexed-ordered
1 | # Vector indexed-ordered load instructions |
unit-stride segment
把一些segment放入连续的vector寄存器里,或从vector寄存器写入segment。
和前面的指令的不同在于,前面的指令是横向放的,segment是纵向放的。
1 | # Format |
该指令的总元素个数 = vl * nf.
举例说明。假设VLEN=128。
1 | li a1, 512 |

unit-stride fault-only-first segment
1 | # Template for vector fault-only-first unit-stride segment loads. |
stride segment
1 | # Format |
indexed-unordered segment
1 | # Format |
indexed-ordered segment
1 | # Format |
vector integer arithmetic instructions
integer arithmetic指令有如下几类。
- Vector Single-Width Integer Add and Subtract
- Vector Widening Integer Add/Subtract
- Vector Integer Extension
- Vector Integer Add-with-Carry / Subtract-with-Borrow Instructions
- Vector Bitwise Logical Instructions
- Vector Single-Width Shift Instructions
- Vector Narrowing Integer Right Shift Instructions
- Vector Integer Compare Instructions
- Vector Integer Min/Max Instructions
- Vector Single-Width Integer Multiply Instructions
- Vector Integer Divide Instructions
- Vector Widening Integer Multiply Instructions
- Vector Single-Width Integer Multiply-Add Instructions
- Vector Widening Integer Multiply-Add Instructions
- Vector Integer Merge Instructions
- Vector Integer Move Instructions
Vector Single-Width Integer Add and Subtract
操作位宽是vtype中的SEW。SEW范围的溢出是被忽略的。
1 | # Integer adds. |
举例说明。假设VLEN=128。
1 | vsetvli t0, a1, e64, m1 |
Vector Widening Integer Add/Subtract
1 | # Widening unsigned integer add/subtract, 2*SEW = SEW +/- SEW |
举例说明。假设VLEN=128。
1 | vsetvli t0, a1, e64, m1 |
Vector Integer Extension
该指令source的EEW取值是 1/2,1/4,1/8 的SEW。dest的EEW等于SEW。
1 | vzext.vf2 vd, vs2, vm # Zero-extend SEW/2 source to SEW destination |
举例说明。假设VLEN=128。
1 | vsetvli t0, a1, e64, m1 |
Vector Integer Add-with-Carry / Subtract-with-Borrow Instructions
1 | # Produce sum with carry. |
1 | # Produce difference with borrow. |
Vector Bitwise Logical Instructions
1 | # Bitwise logical operations. |
Vector Single-Width Shift Instructions
1 | # Bit shift operations |
Vector Narrowing Integer Right Shift Instructions
1 | # Narrowing shift right logical, SEW = (2*SEW) >> SEW |
Vector Integer Compare Instructions
1 | # Set if equal |
Vector Integer Min/Max Instructions
1 | # Unsigned minimum |
Vector Single-Width Integer Multiply Instructions
1 | # Signed multiply, returning low bits of product |
Vector Integer Divide Instructions
1 | # Unsigned divide. |
Vector Widening Integer Multiply Instructions
1 | # Widening signed-integer multiply |
Vector Single-Width Integer Multiply-Add Instructions
1 | # Integer multiply-add, overwrite addend |
Vector Widening Integer Multiply-Add Instructions
1 | # Widening unsigned-integer multiply-add, overwrite addend |
Vector Integer Merge Instructions
1 | vmerge.vvm vd, vs2, vs1, v0 # vd[i] = v0.mask[i] ? vs1[i] : vs2[i] |
Vector Integer Move Instructions
1 | vmv.v.v vd, vs1 # vd[i] = vs1[i] |
vector fixed-point arithmetic instructions
fixed-point arithmetic指令有如下几类。
- Vector Single-Width Saturating Add and Subtract
- Vector Single-Width Averaging Add and Subtract
- Vector Single-Width Fractional Multiply with Rounding and Saturation
- Vector Single-Width Scaling Shift Instructions
- Vector Narrowing Fixed-Point Clip Instructions
vector floating-point arithmetic instructions
floating-point arithmetic指令有如下几类。
- Vector Floating-Point Exception Flags
- Vector Single-Width Floating-Point Add/Subtract Instructions
- Vector Widening Floating-Point Add/Subtract Instructions
- Vector Single-Width Floating-Point Multiply/Divide Instructions
- Vector Widening Floating-Point Multiply
- Vector Single-Width Floating-Point Fused Multiply-Add Instructions
- Vector Widening Floating-Point Fused Multiply-Add Instructions
- Vector Floating-Point Square-Root Instruction
- Vector Floating-Point Reciprocal Square-Root Estimate Instruction
- Vector Floating-Point Reciprocal Estimate Instruction
- Vector Floating-Point MIN/MAX Instructions
- Vector Floating-Point Sign-Injection Instructions
- Vector Floating-Point Compare Instructions
- Vector Floating-Point Classify Instruction
- Vector Floating-Point Merge Instruction
- Vector Floating-Point Move Instruction
- Single-Width Floating-Point/Integer Type-Convert Instructions
- Widening Floating-Point/Integer Type-Convert Instructions
- Narrowing Floating-Point/Integer Type-Convert Instructions
vector reduction instructions
reduction指令有如下几类。
- Vector Single-Width Integer Reduction Instructions
- Vector Widening Integer Reduction Instructions
- Vector Single-Width Floating-Point Reduction Instructions
- Vector Widening Floating-Point Reduction Instructions
这些指令有如下特点:
- reduction操作如果vstart!=0,会发生异常
Vector Single-Width Integer Reduction Instructions
该指令的srouce/dest宽度都是SEW。
1 | # Simple reductions, where [*] denotes all active elements: |
Vector Widening Integer Reduction Instructions
1 | # Unsigned sum reduction into double-width accumulator |
Vector Single-Width Floating-Point Reduction Instructions
1 | # Simple reductions. |
Vector Widening Floating-Point Reduction Instructions
1 | # Simple reductions. |
vector mask instructions
mask指令有如下几类。
- Vector Mask-Register Logical Instructions
- Vector count population in mask vcpop.m
- vfirst find-first-set mask bit
- vmsbf.m set-before-first mask bit
- vmsif.m set-including-first mask bit
- vmsof.m set-only-first mask bit
- Vector Iota Instruction
- Vector Element Index Instruction
Vector Mask-Register Logical Instructions
这些指令有如下特点:
- 所有mask register中每个元素都是1bit的
- 这些指令所操作的都是单个vector寄存器,和vtype中vlmul无关,且不改变vlmul。
- 这些指令都是unmasked的,所以没有inactive elements。
1 | vmand.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] && vs1.mask[i] |
Vector count population in mask vcpop.m
1 | vcpop.m rd, vs2, v0.t # x[rd] = sum_i ( vs2.mask[i] && v0.mask[i] ) |
vfirst find-first-set mask bit
1 | vfirst.m rd, vs2, vm |
vmsbf.m set-before-first mask bit
1 | vmsbf.m vd, vs2, vm |
vmsif.m set-including-first mask bit
1 | vmsif.m vd, vs2, vm |
vmsof.m set-only-first mask bit
1 | vmsof.m vd, vs2, vm |
Vector Iota Instruction
1 | viota.m vd, vs2, vm |
Vector Element Index Instruction
1 | vid.v vd, vm # Write element ID to destination. |
vector permutation instructions
permutation指令有如下几类。
- Integer Scalar Move Instructions
- Floating-Point Scalar Move Instructions
- Vector Slide Instructions
- Vector Register Gather Instructions
- Vector Compress Instruction
- Whole Vector Register Move
Integer Scalar Move Instructions
该指令忽略LMUL,move单个SEW宽度的元素。
如果SEW > XLEN,只有低位XLEN的长度才被move。
如果SEW < XLEN,sign-extended to XLEN。
1 | vmv.x.s rd, vs2 # x[rd] = vs2[0] (vs1=0) |
Floating-Point Scalar Move Instructions
1 | vfmv.f.s rd, vs2 # f[rd] = vs2[0] (rs1=0) |
Vector Slide Instructions
1 | # slideup |
Vector Register Gather Instructions
1 | vrgather.vv vd, vs2, vs1, vm # vd[i] = (vs1[i] >= VLMAX) ? 0 : vs2[vs1[i]]; |
Vector Compress Instruction
1 | vcompress.vm vd, vs2, vs1 # Compress into vd elements of vs2 where vs1 is enabled |
Whole Vector Register Move
1 | vmv<nr>r.v vd, vs2 # General form |