Introduce riscv spinlock and rwlock.
spin lock
spin lock是,当无法获得锁的时候,会原地打转,等待资源,直到获得锁之后,才会往下走,进去临界区。
spinlock提供三个函数:初始化锁,加锁,解锁。
1 | spinlock_t lock; |
另外还有几个函数变种
1 | spin_lock_irq() // 在使用spinlock的同时禁止中断,释放时打开中断 |
变种都是在基础函数之上做的扩展,我们只分析基础函数。
spinlock_t 定义在 arch/riscv/include/asm/spinlock_types.h
1 | typedef struct { |
从定义可以看出,riscv架构下的spinlock并没有保证公平抢锁,只是定义了一个变量而已。这里和arm是不一样的。arm中spinlock是有定义owner和next变量,用来对锁请求进行排序,从而保证先到先得。而riscv的实现目前还是在锁释放的时刻,所有请求一起去抢,谁抢到是谁的,这种机制。
lock和unlock函数在arch/riscv/include/asm/spinlock.h
1 | /* |
可以看出,riscv架构下的spinlock是使用amoswap指令完成的。
再看下_raw_spin_lock反汇编。
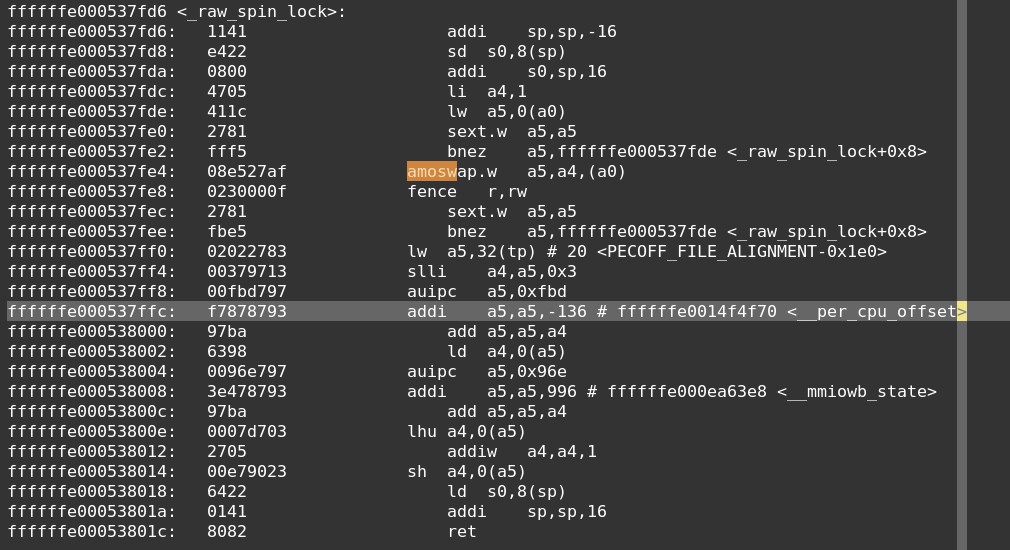
其核心主要是这几条指令:
1 | li a4, 1 |
再看下解锁的反汇编:
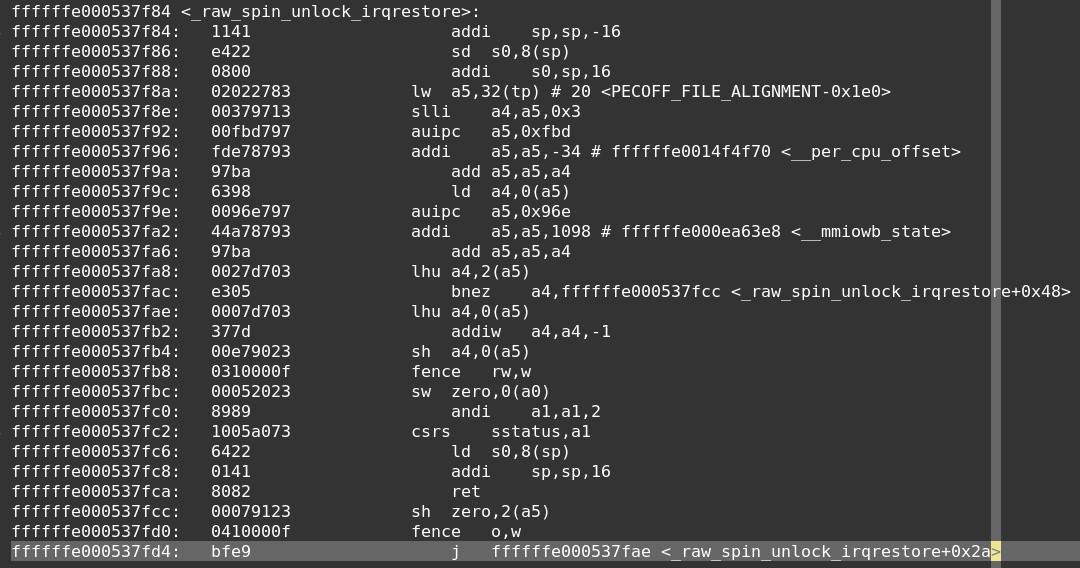
其核心就是一条store指令。
1 | fence rw, w |
举一个双核抢锁的例子来说明:
1 | hart0 hart 1 |
rw lock
上面的spinlock是在只要有资源请求之前,就需要抢到锁,再进行操作。而在很多场景下,只需要对资源进行读,而不需要写,这些读请求,理论上是可以允许多个人同时进行读取的,而只有写才需要只允许一个人写。读写锁rwlock就是为这些需求定制的。可以达到提高并发性能的目的。
加锁逻辑是:
- 如果没有读写请求时,读和写都能抢到锁,但只能其中一个抢到
- 如果有读请求时,写不能进入,新来的读可以进入
- 如果有写请求时,新来的写和读都不能进入
- 如果有一个或多个读请求时,写不能抢占,要等到所有读都释放,写才可以进入
解锁逻辑时:
- 写解锁时,所有读写请求同时抢占,谁抢到是谁的
- 读解锁时,如果还有读请求在锁中,只有读可以继续抢占;如果没有读请求了,读和写都可以抢占。
基础的函数是:
1 | read_lock() |
当然,也有一些变种,就不详细列举了。
arch_rwlock_t 定义在 arch/riscv/include/asm/spinlock_types.h
1 | typedef struct { |
从定义可以看出,也是只定义了一个lock变量。
lock和unlock函数在arch/riscv/include/asm/spinlock.h
1 | static inline void arch_read_lock(arch_rwlock_t *lock) |
主要分析几个基础函数。
read_lock反汇编如下:
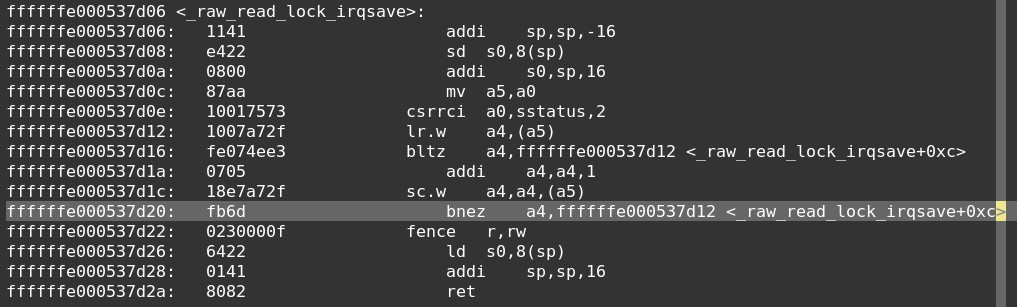
write_lock反汇编如下:
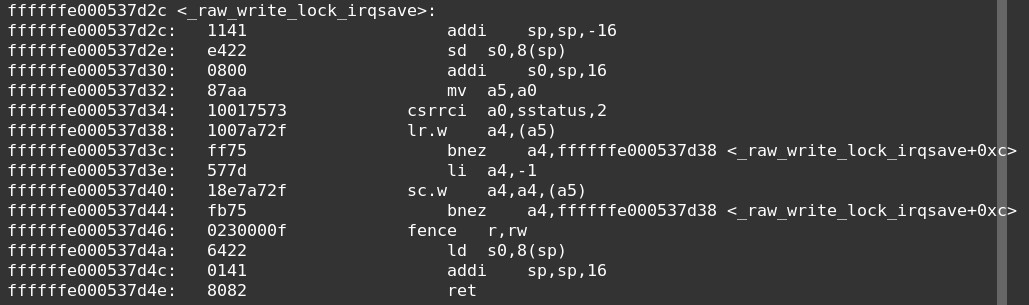
read unlock 反汇编如下:
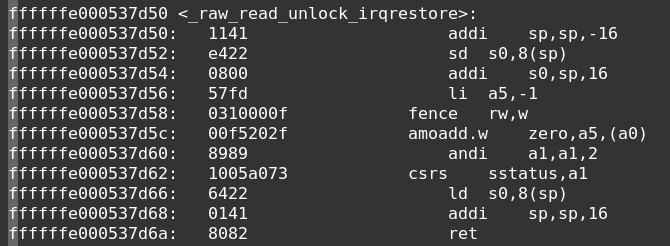
write unlock反汇编如下:
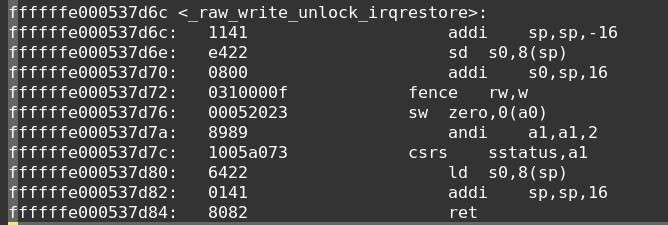
从上述代码可以分析出如下点:
- lock=0,表示没有人占用,read/write都可以抢
- lock>0,表示read占用了,lock的值就代表有多少个read占用了
- lock=-1,表示write占用了,只能有一个write占用,所以只可能是-1
- read lock时
- 如果lock<0就要等,表示有write占用住了
- 如果lock<=0,可以进入,将lock+1写入lock,表示read多了一个。
- 如果sc成功,进入临界区
- 如果sc失败,重新走一次流程
- write lock时
- 如果lock不等于0,表示有write或者read占住了,要等
- 如果lock等于0,将-1写入lock
- 如果sc成功,表示占住了锁,进入临界区
- 如果sc失败,表示没抢到锁,重新走一次流程
- read unlock时
- 使用amoadd指令,将lock-1,写入lock,表示释放掉一个read源
- write unlock时
- 使用sw指令,将lock写为0,表示释放掉write源
Update
在2022/3/21之后的linux代码,已经将上述代码删除了,合并到了架构统一的代码中了。
commit id: 19bc59bbed
spinlock
spinlock的代码被移到了:include/asm-generic/spinlock.h
1 | static __always_inline void arch_spin_lock(arch_spinlock_t *lock) |
这套代码和之前的机制完全不一样了。这里使用的是amoadd来实现的。工作过程是
- 使用高16bits表示allocated的个数,使用低16bits表示de-allocated的个数。
- 如果高16bits和低16bits相等,表示没有人占用
- 如果高16bits和低16bits不相等,表示有人占住了锁。
- lock的过程
- 将lock的高16bits增加1
- 再读取lock的值
- 如果原来的高16bits和低16bits相等,表示本次我抢到了锁,直接返回
- 如果不相等,表示有其他人和我一起抢锁,我没抢到,进入循环,一直读取lock的值,直到低16bits和原来的高16bits相等,说明我等到了锁。
- 可以看出,这样实现,是可以对抢锁的源进行排序的。比之前的代码好。
- unlock的过程
- 读取lock的值,将低16bits加1。
举个例子:
1 | hart0 hart1 |
rwlock
rwlock的代码被移到了:include/asm-generic/qspinlock.h
1 | /** |
和原来的代码机制类似。工作过程是:
lock[8:0] 给write用,lock[31:9]给read用
read_lock时,将lock[31:9] + 1。
read_unlock时,将lock[31:9] - 1。
write lock时,将lock[8:0]写为0xff
write unlock时,将lock[8:0]写为0
当read/write lock获取失败的时候,会进入slowpath,slowpath中会配合一个spinlock来完成。
代码在:
kernel/locking/qrwlock.c